How to Deploy Your Rig App on AWS Lambda: A Step-by-Step Guide
TL;DR
- A step-by-step walkthrough on deploying a simple AI Agent built with Rig, a fullstack agent framework, on AWS Lambda using the cargo lambda CLI.
- Comparison of performance metrics (memory usage, execution time, and cold starts) with a similar deployed Agent built with LangChain.
- Rig vs. Langchain agent on AWS Lambda
- 🪶 Lower memory footprint (~26MB vs ~130MB)
- ⏩ Faster cold starts (90ms vs. 1900ms)
- 🧘♂️ More consistent performance across memory configuration
Welcome to the series Deploy Your Rig Application! Apps built with Rig can vary in complexity across three core dimensions: LLM usage, knowledge bases for RAG, and the compute infrastructure where the application is deployed. In this series, we’ll explore how different combinations of these dimensions can be configured for production use.
Today, we’ll start with a simple Rig agent that uses the OpenAI model GPT-4-turbo, does not rely on a vector store (ie.: no RAGing), and will be deployed on AWS Lambda.
This blog will provide a step-by-step deployment guide for the simple Rig app, showcase performance metrics of the Rig app running on AWS Lambda, and compare these metrics with those of a LangChain app on the same platform.
💡 If you’re new to Rig and want to start from the beginning or are looking for additional tutorials, check out our blog series.
Let’s dive in!
Prerequisites
Before we begin building, ensure you have the following:
- A clone of the
rig-entertainer-lambdacrate (or your own Rig application). - An AWS account
- An Open AI api key
AWS Lambda Quick Overview
You might deploy your Rust application on AWS lambda if it’s a task that can execute in under 15 mins or if your app is a REST API backend.
AWS 🤝 Rust
AWS Lambda supports Rust through the use of the OS-only runtime Amazon Linux 2023 (a lambda runtime) in conjunction with the Rust runtime client, a rust crate.
REST API backend
- Use the
lambda-httpcrate (from the runtime client) to write your function’s entrypoint. - Then, route traffic to your lambda via AWS API services like Api Gateway, App Sync, VPC lattice, etc …
- If your lambda handles multiple endpoints of your API, the crate axum facilitates the routing within the lambda.
Event based task (15 mins max.)
- Your lambda function is invoked by some event with the event passed as the payload. For example, configure your S3 bucket to trigger the lambda function when a new object is added to the bucket. The function will receive the new object in the payload and can further process it.
- Use the
lambda_runtimecrate withlambda_events(from the runtime client) to write your function’s entrypoint. - Then, invoke your function either via
lambda invokecommand or with integrated AWS triggers (ie. S3 UploadObject trigger).
For both cases, the crate
tokiomust also be added to your project as the lambda runtime client usestokioto handle asynchronous calls.
Rig Entertainer Agent App 🤡
The crate rig-entertainer-lambda implements a simple Rust program that is executed via the lambda_runtime. It invokes a Rig agent using the OpenAI API, to entertain users with jokes. It is an event-based task that I will execute with the lambda invoke command.
The main takeaway here is that the app’s Cargo.toml file must include the following dependencies:
rig-core(our rig crate)lambda_runtimetokio
Now let’s deploy it
There are many ways to deploy Rust lambdas to AWS. Some out of the box options include the AWS CLI, the cargo lambda CLI, the AWS SAM CLI, the AWS CDK, and more. You can also decide to create a Dockerfile for your app and use that container image in your Lambda function instead. See some useful examples here.
In this blog, we’ll use the cargo lambda CLI option to deploy the code in rig-entertainer-rust from your local machine to an AWS lambda:
# Add your AWS credentials to your terminal
# Create an AWS Lambda function named ‘rig-entertainer’ with architecture x86_64.
function_name='rig-entertainer'
cd rig-entertainer-lambda
cargo lambda build --release # Can define different architectures here with --arm64 for example
cargo lambda deploy $function_name # Since the name of the crate is the same as the the lambda function name, no need to specify a binary fileMetrics on the cloud ☁️
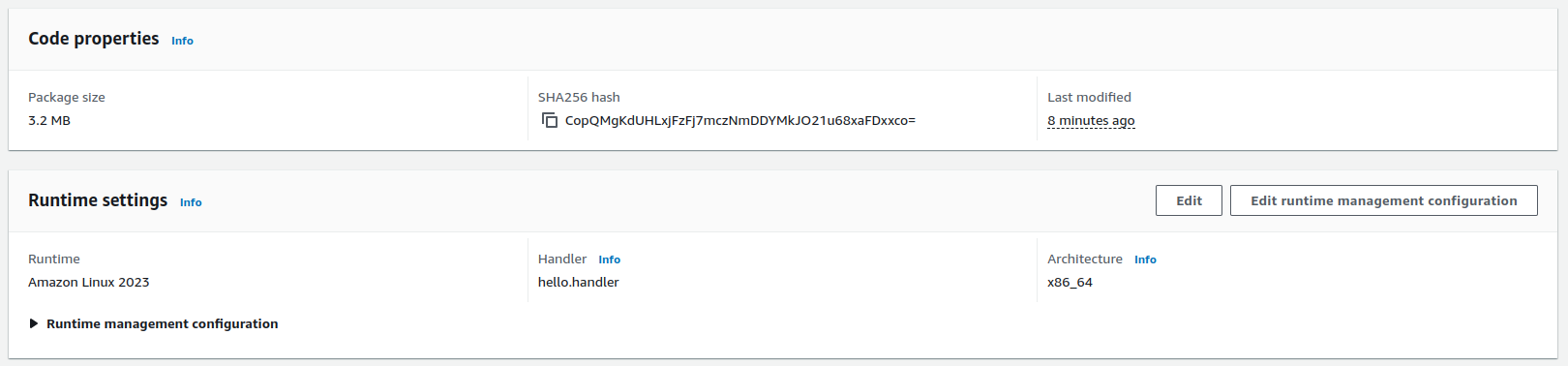
Deployment package
This is the code configuration of the rig-entertainer function in AWS. The function’s code package (bundled code and dependencies required for lambda to run) includes the single rust binary called bootstrap, which is 3.2 MB.
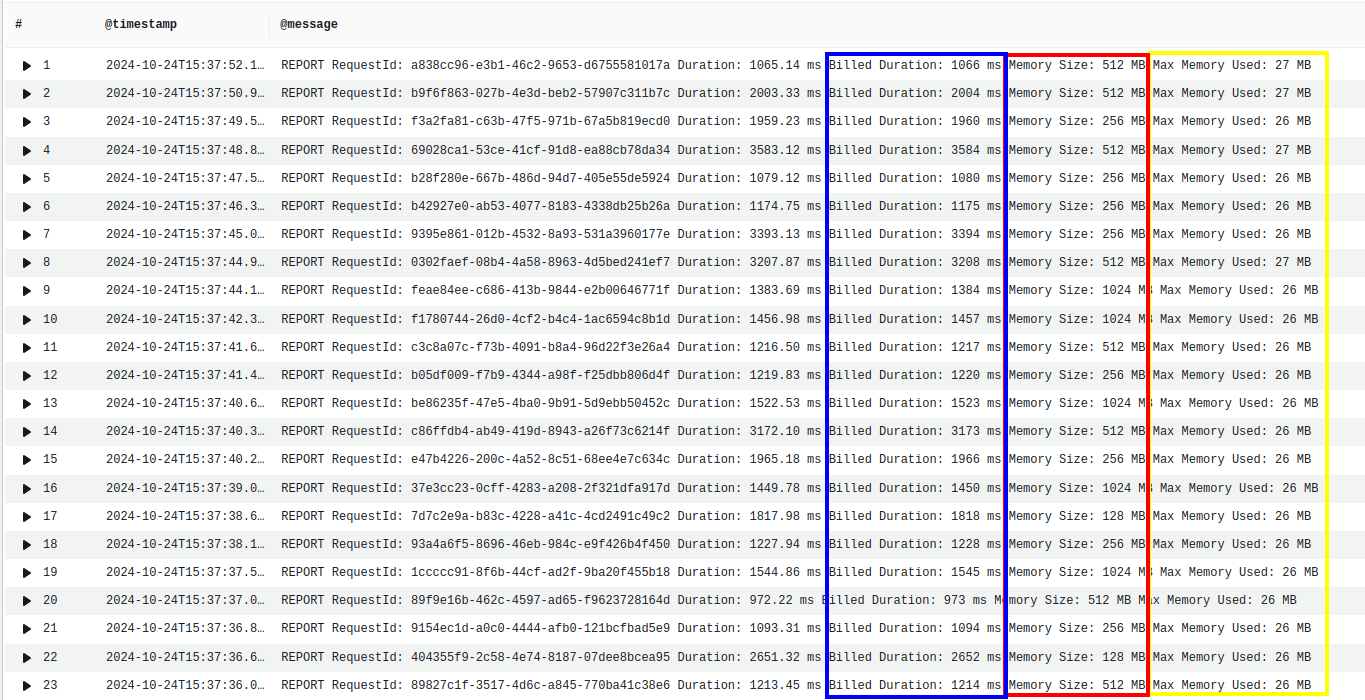
Memory, CPU, and runtime
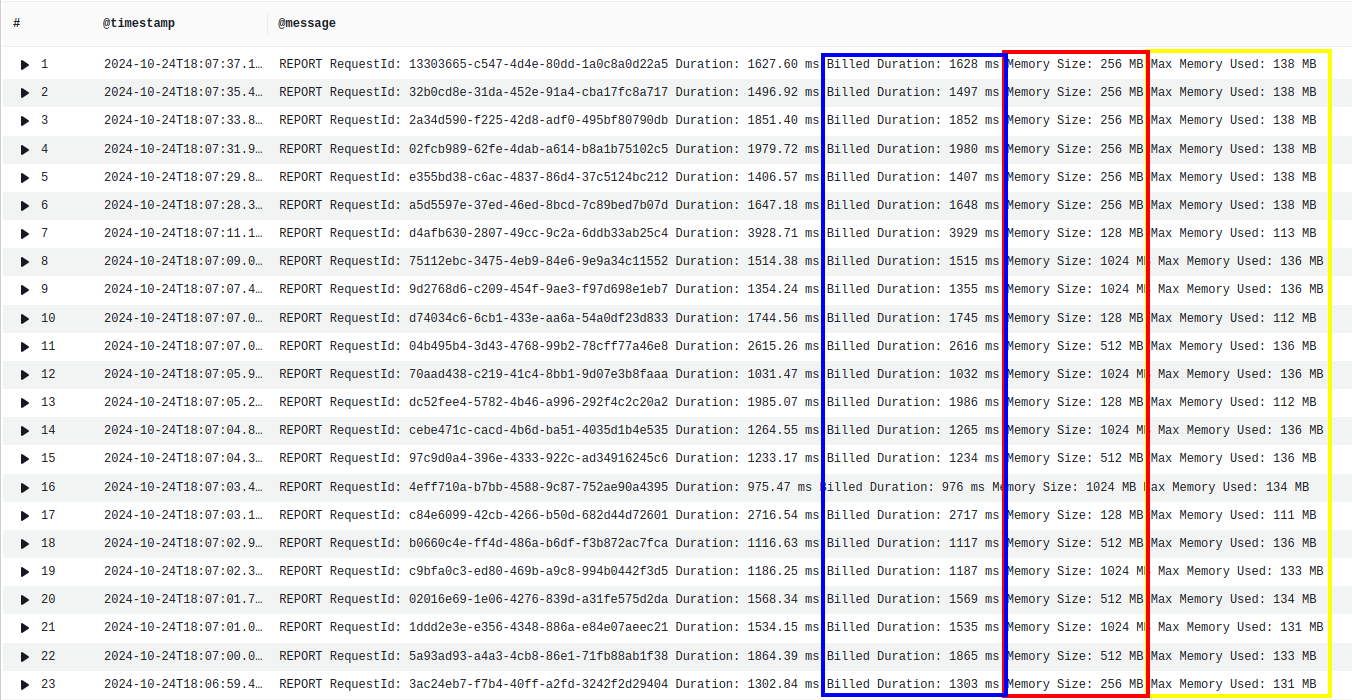
The image below gives metrics on memory usage and execution time of the function. Each row represents a single execution of the function. In yellow is the total memory used, in red is the amount of memory allocated, and in blue is the runtime.
Although the lambda has many configuration options for the memory ranging from 128MB to 1024MB, we can see that the average memory used by our app is 26MB.
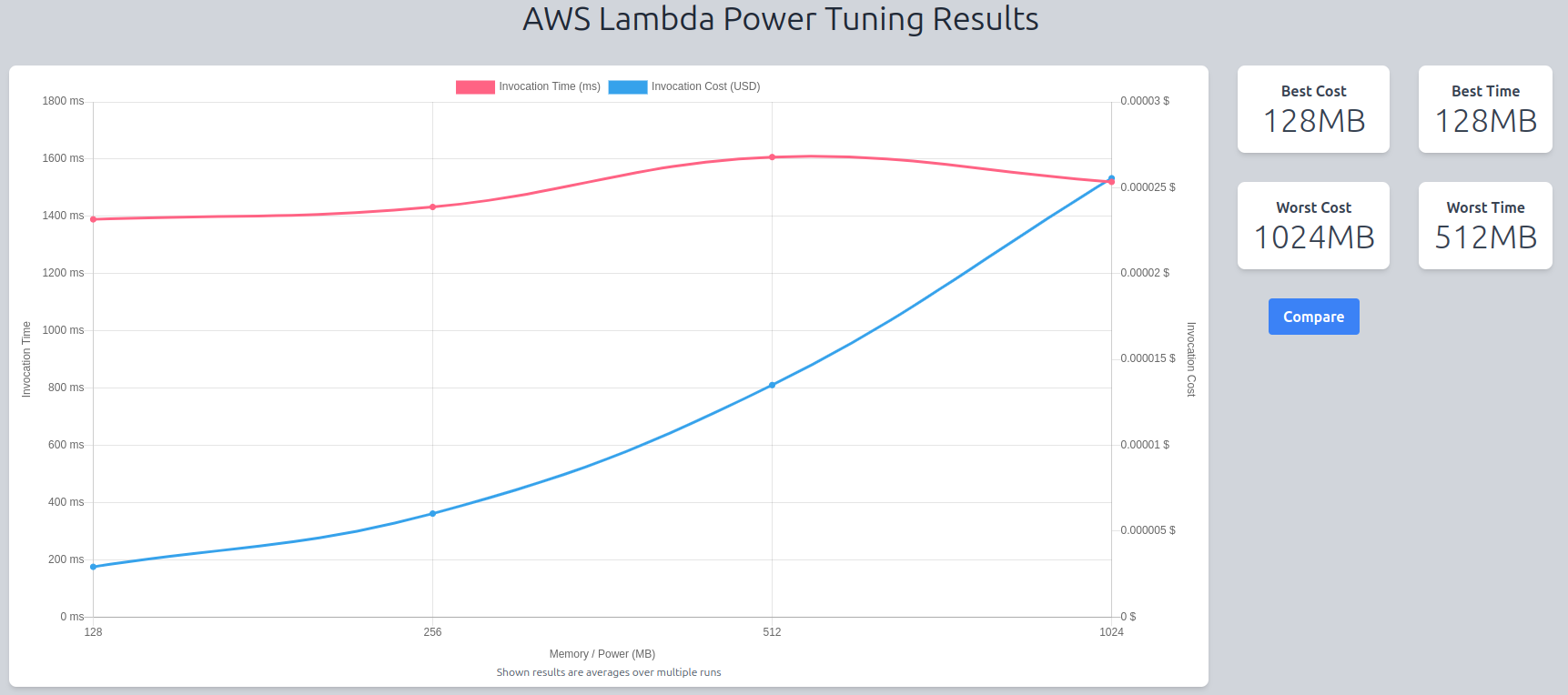
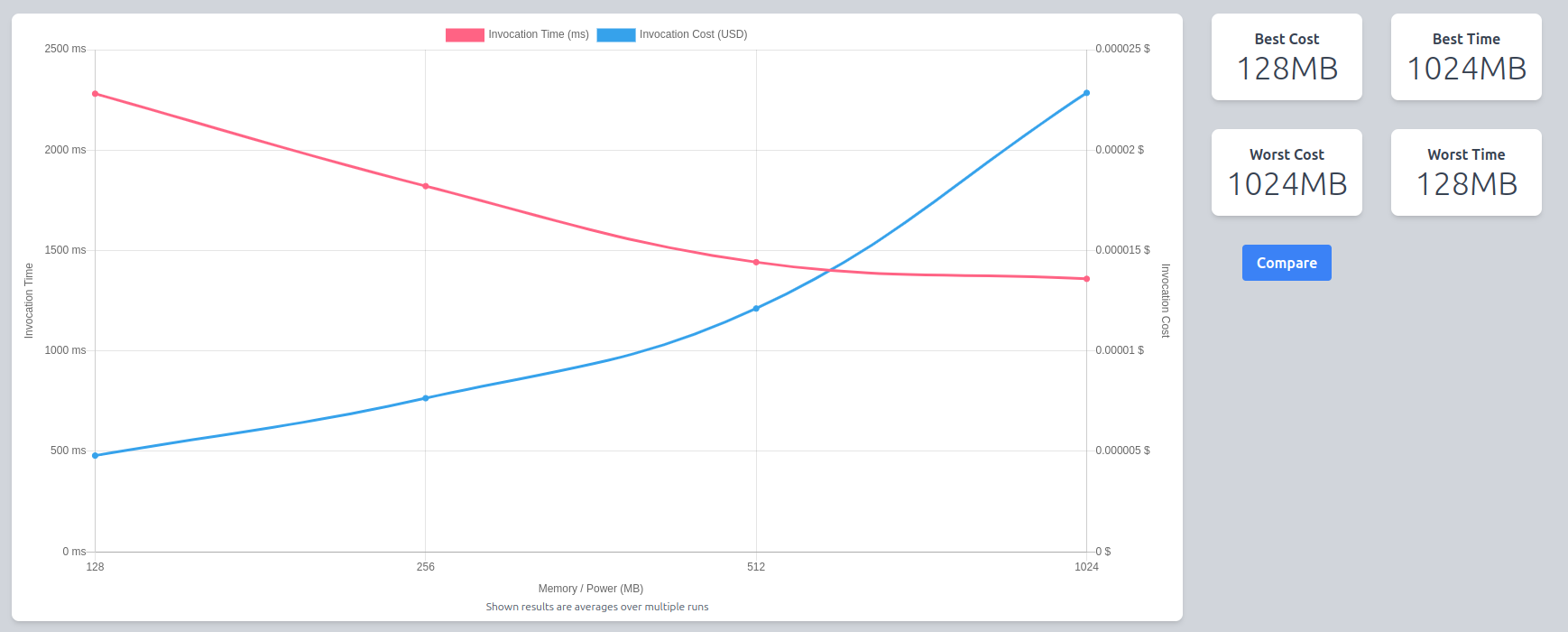
Let’s get more information on the metrics above by spamming the function and calculating averages. I invoked rig-entertainer 50 times for each memory configuration of 128MB, 256MB, 512MB, 1024MB using the power tuner tool and the result of those invocations are displayed in the chart below.
The x-axis is the memory allocation, and the y-axis is the average runtime over the 50 executions of rig-entertainer.
Q. We know that the function uses on average only 26MB per execution (which is less than the minimum memory allocation of 128MB) so why should we test higher memory configurations? A. vCPUs are added to the lambda in proportion to memory so adding memory could still affect the performance.
However, we can see that adding memory to the function (and therefore adding computational power) does not affect its performance at all. Since the cost of a lambda execution is calculated in GB-seconds, we get the most efficient lambda for the lowest price!
Cold starts ❄️
Cold starts occur when the lambda function’s execution environment needs to be booted up from scratch. This includes setting up the actual compute that the lambda function is running on, and downloading the lambda function code and dependencies in that environment. Cold start latency doesn’t affect all function executions because once the lambda environment has been setup, it will be reused by subsequent executions of the same lambda.
In the lambda cloudwatch logs, if a function execution requires a cold start, we see the Init Duration metric at the end of the execution.
For rig-entertainer, we can see that the average cold start time is 90.9ms:
 Note that the function was affected by cold starts 9 times out of the 245 times it was executed, so 0.036% of the time.
Note that the function was affected by cold starts 9 times out of the 245 times it was executed, so 0.036% of the time.
Langchain Entertainer Agent App 🐍
We replicated the OpenAI entertainer agent using the langchain python library in this mini python app which is also deployed to AWS Lambda in a function called langchain-entertainer.
Let’s compare the metrics outlined above.
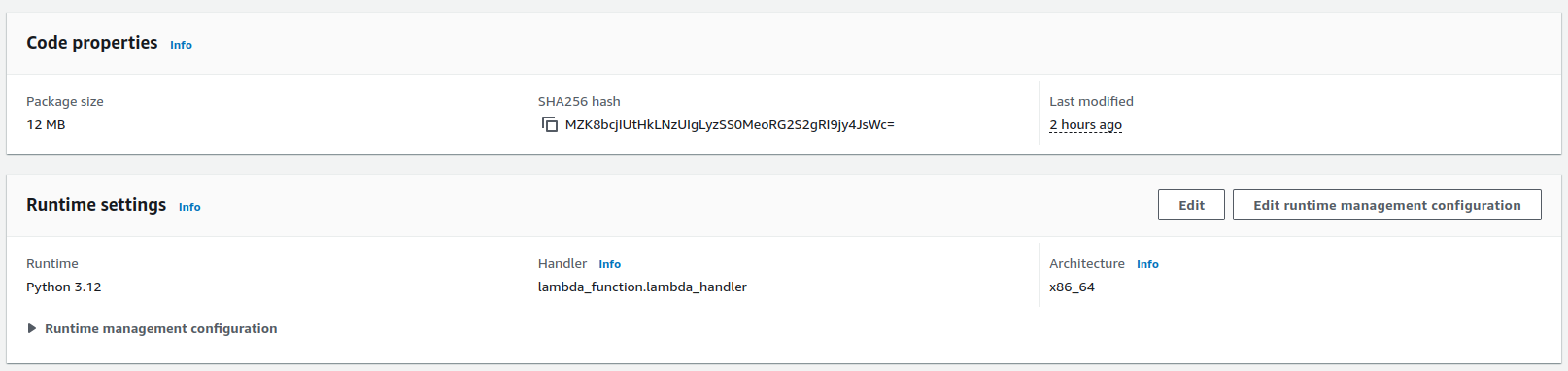
Deployment package
This is the code configuration of the langchain-entertainer function in AWS. The function’s code package is a zip file including the lambda function code and all dependencies required for the lambda program to run.
Memory, CPU, and runtime
There are varying memory configurations from 128MB, 256MB, 512MB, to 1024MB for the lambda shown in the table below. When 128MB of memory is allocated, on average about 112MB of memory is used, and when more more than 128MB is allocated, about 130MB of memory is used and the runtime is lower.
Let’s get some more averages for these metrics: I invoked langchain-entertainer 50 times for each memory configuration of 128MB, 256MB, 512MB, 1024MB using the power tuner tool and the result of those invocations were plotted in the graph below.
We can see that by increasing the memory allocation (and therefore computation power) of langchain-entertainer, the function becomes more performant (lower runtime). However, note that since you pay per GB-seconds, a more performant function is more expensive.
Cold starts ❄️
For langchain-entertainer, the average cold start time is: 1,898.52ms, ie. 20x as much as the rig app coldstart.
 Note that the function was affected by cold starts 6 times out of the 202 times it was executed, so 0.029% of the time.
Note that the function was affected by cold starts 6 times out of the 202 times it was executed, so 0.029% of the time.