⚡🦀 Deploy a blazing-fast & Lightweight LLM app with Rust-Rig-LanceDB
TL;DR
- A step-by-step walkthrough on deploying a LLM app using
Rig&LanceDBon AWS Lambda. You’ll learn how to prepare your app, choose the right storage backend (like S3 or EFS), and optimize performance by efficiently using cloud metrics. - Stats: Rig RAG Agent using LanceDB on AWS :
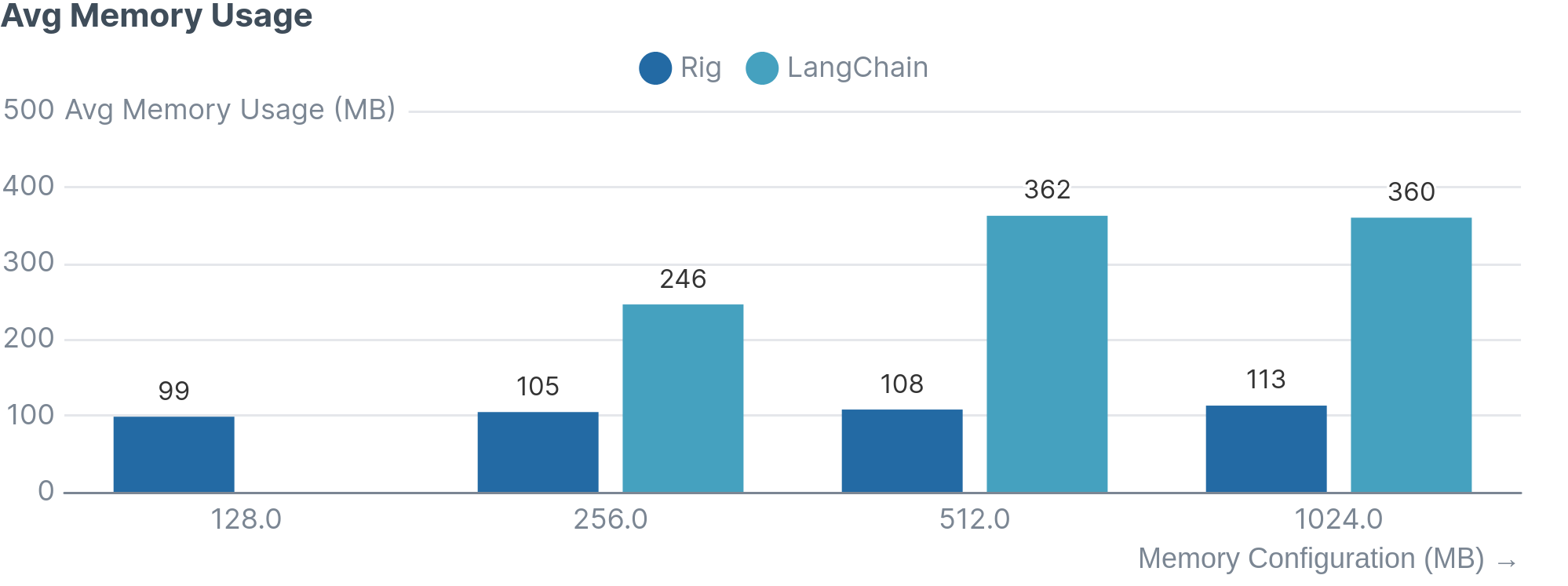
- Low memory usage (96MB - 113MB)
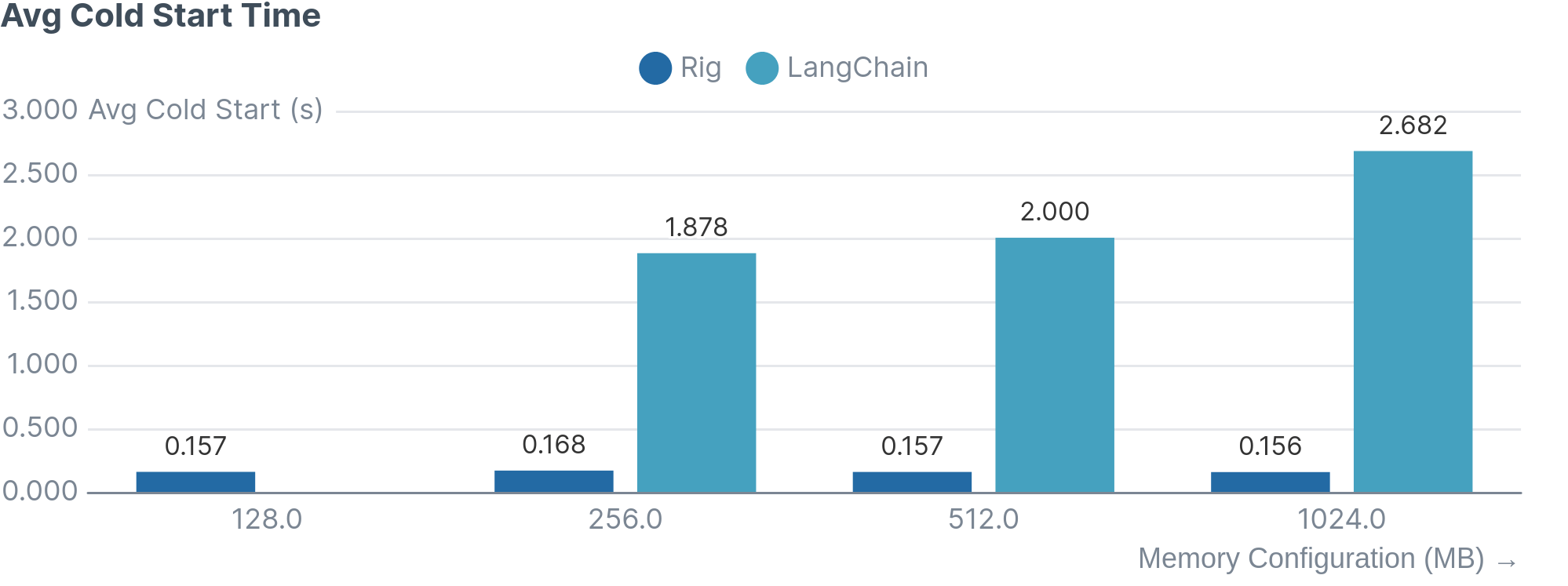
- Fast cold starts (consistently 160ms)
- Stats: LangChain RAG Agent using LanceDB on AWS:
- Higher memory usage (246MB - 360MB)
- Slower cold starts (1,900ms - 2,700ms)
- Jump to Metrics ⏬
Welcome back to Deploy Your Rig Application! Apps built with Rig vary in complexity based on LLM usage, vector databases for RAG, and infrastructure deployment. This series explores various configurations for production use.
⭐ Today’s Highlight: Rig’s LanceDB integration! ⭐
We’ll deploy a Rig agent using OpenAI’s text-embedding-ada-002 and GPT-4o, relying on the LanceDB vector store and deployed on AWS Lambda.
💡 If you’re new to Rig and want to start from the beginning or are looking for additional tutorials, check out our blog series.
Let’s dive in!
Prerequisites
Before we begin building, ensure you have the following:
❗ We will not be covering how to write your RAG app with Rig, only how to deploy it. So make sure you read this tutorial first to help you code your application.
- A clone of the
rig-montreal-lancedbcrate which includes two separate binaries: aloader(writes data to LanceDB) and anapp(performs RAG on LanceDB). - An AWS account and some background knowledge on deployments on AWS, including Cloudformation templates
- An OpenAI api key
Our use case: Montreal 🌇
The app in rig-montreal-lancedb RAGs data from montreal open data. The Montréal municipality generates and manages large quantities of data through its activities, such as data about agriculture, politics, transportation, health and much more. The open data app publishes all these datasets and make them freely accessible to all citizens! Our app will index the metadata of all the public datasets so that a user can ask questions pertaining to the open data.
The loader binary indexes all dataset metadata (name, description, tags, …) into LanceDB and the app binary performs vector search on the data based on a prompt. For example:
Prompt: Give me information on gaseous pollutants in Montreal. How are the concentrations measured? App answer: The concentrations of gaseous pollutants in Montreal are measured through the Réseau de surveillance de la qualité de l’air (RSQA), which is a network of measurement stations located on the Island of Montreal. These stations continuously determine the atmospheric concentration of various pollutants. The data is transmitted via telemetry, …
LanceDB Quick Overview 💾
Lance is an open-source columnar data format designed for performant ML workloads.
- Written in Rust 🦀.
- Native support for storing, querying and filtering vectors, deeply nested data and multi-modal data (text, images, videos, point clouds, and more).
- Support for vector similarity search, full-text search and SQL.
- Interoperable with other columnar formats (such as Parquet) via Arrow
- Disk-based indexes and storage.
- Built to scale to hundreds of terabytes of data.
LanceDB is an open-source vector database.
- Written in Rust 🦀.
- Built on top of Lance.
- Support for Python, JavaScript, and Rust client libraries to interact with the database.
- Allows storage of raw data, metadata, and embeddings all at once.
LanceDB Storage Options
LanceDB’s underlying optimized storage format, lance, is flexible enough to be supported by various storage backends, such as local NVMe, EBS, EFS, S3 and other third-party APIs that connect to the cloud.
💡 All you need to do to use a specific storage backend is define its connection string in the LanceDB client!
Let’s go through some storage options that are compatible with AWS Lambda!
S3 - Object Store
❕Data is stored as individual objects all at the same level. ❕Objects are kept track of by a distributed hash table (DHT), where each object is identified by a unique ID.
| Pros of Object Stores | Cons of Object Stores |
|---|---|
| Unlimited scaling ♾️: Objects can be stored across distributed systems, eliminating single-node limitations. This is ideal for ML and AI applications handling large data volumes. | Higher latency 🚚: Accessing a remote object store over a network via HTTP/HTTPS adds overhead compared to file system protocols like NFS. Additionally, storing metadata separately from objects introduces some retrieval latency. |
| Cheap 💸: The simple storage design makes it more affordable than traditional file systems. | |
| Highly available and resilient 💪: Affordable storage allows for redundant data storage within and across data centers. |
S3 + LanceDB setup on AWS lambda
⚠️ Important: S3 does not support concurrent writes. If multiple processes attempt to write to the same table simultaneously, it could lead to data corruption. But there’s a solution! Use the DynamoDB commit store feature in LanceDB to prevent this.
Part I - Write lambda function code
- Create an S3 Bucket where your Lance database will be stored. Ours is called:
rig-montreal-lancedb. - In the lambda code, connect to the store via the
LanceBD clientas so:
// Note: Create s3://rig-montreal-lancedb bucket beforehand
let db = lancedb::connect("s3://rig-montreal-lancedb").execute().await?;
// OR
let db = lancedb::connect("s3+ddb://rig-montreal-lancedb?ddbTableName=my-dynamodb-table").execute().await?;Part II - Deploy lambdas
💡 Need a refresher on Lambda deployments? Check out our previous blog for a full walkthrough.
# Lambda that writes to the store
cargo lambda build --release --bin loader
cargo lambda deploy --binary-name loader <your_loader_function_name>
# Lambda that reads to the store
cargo lambda build --release --bin app
cargo lambda deploy --binary-name app <your_app_function_name>💡 Don’t forget to set the necessary IAM permissions! Your lambda functions need appropriate access to the S3 bucket — whether it’s read, write, or both.
Lambda ephemeral storage - Local file system
Lambda ephemeral storage is temporary and unique to each execution environment, it is not intended for persistent storage. In other words, any LanceDB store created during the lambda execution on ephemeral storage will be wiped when the function cold starts. This option can be used for very specific use cases (mostly for testing) where writing to the store needs to be done in the same process as reading, and data is only read by a single lambda execution.
Ephemeral storage in a lambda is found in the /tmp directory. All you need to do is:
let db = lancedb::connect("/tmp").execute().await?;EFS - Virtual file system
❕A serverless, elastic, shared file system designed to be consumed by AWS services like EC2 and Lambda. ❕Data is persisted and can be shared across lambda invocations (unlike the S3 without commit store and ephemeral storage options above). ❕Supports up to 25,000 concurrent connections.
| Pros of EFS | Cons of EFS |
|---|---|
| Stateful lambda: Mounting an EFS instance on a lambda function provides knowledge of previous and concurrent executions. | Development time: More involved cloud setup |
| Low latency ⚡: A lambda function resides in the same VPC as the EFS instance, allowing low-latency network calls via the NFS protocol. | Cost 💲: More expensive than S3 |
EFS + LanceDB setup on AWS Lambda
💡 Setting up EFS in the cloud can be intricate, so you can use our CloudFormation template to streamline the deployment process.
Part I - Build Rust code and upload zip files to S3
In the lambda code, connect to the store via the LanceBD client as so:
let db = lancedb::connect("/mnt/efs").execute().await?;Then, compile your code, zip the binaries, and upload them to S3:
# Can also do this directly on the AWS console
aws s3api create-bucket --bucket <your_bucket_name>
cargo lambda build --release --bin loader
cargo lambda build --release --bin app
cd target/lambda/loader
zip -r bootstrap.zip bootstrap
# Can also do this directly on the AWS console
aws s3 cp bootstrap.zip s3://<your_bucket_name>/rig/loader/
cd ..
zip -r bootstrap.zip bootstrap
# Can also do this directly on the AWS console
aws s3 cp bootstrap.zip s3://<your_bucket_name>/rig/app/
Part II - Understand Cloudformation template
The template assumes that your AWS account already has the following resources:
- A VPC with at least two private subnets in separate availability zones, each with public internet access.
- An S3 bucket (as created in Part I) for storing Lambda code.
💡 If you’re missing these resources, follow this AWS tutorial to set up a basic VPC and subnets.
EFS setup
- Mount Targets: Create two mount targets for your EFS instance — one in each subnet (specified in
Parameterssection of CFT template). - Security Groups: Set up an EFS security group with rules to allow NFS traffic from your Lambda functions’ security group.
Lambda functions setup
- Loader and App Lambdas: Deploy both Lambda functions (
loaderandapp) in the same subnets as your EFS mount targets. - Security Groups: Assign a security group that enables access to the EFS security group and public internet.
- EFS Mounting: Configure the Lambdas to mount the EFS targets at
/mnt/efs.
💡 Once everything’s ready, deploy the CloudFormation template to launch your environment with just one click!
Metrics on the cloud ☁️
If you’ve made it to here, you have the Montreal rig app with EFS as the LanceDbB storage backend deployed on AWS Lambda! 🎉 Now we want to look at some metrics when the app is run in the cloud.
For reference, we replicated the Montreal agent using langchain 🐍 in this python project which contains the source code for the loader and app lambdas. The python app uses the same LanceDB vector store on the same EFS instance as the Rig app. To see how the python app was configured in the cloud, take a look at the CloudFormation template.
Let’s compare them!
Rig - Memory, runtime, and coldstarts
We invoked the app function 50 times for each memory configuration of 128MB, 256MB, 512MB, 1024MB using the power tuner tool.
The Cloudwatch query below gathers averages about runtime, memory usage, and cold starts of the lambda over the 50 invocations.
filter @type = "REPORT"
| stats
avg(@maxMemoryUsed) / 1000000 as MemoryUsageMB,
avg(@duration) / 1000 as AvgDurationSec,
max(@duration) / 1000 as MaxDurationSec,
min(@duration) / 1000 as MinDurationSec,
avg(@initDuration) / 1000 as AvgColdStartTimeSec,
count(*) as NumberOfInvocations,
sum(@initDuration > 0) as ColdStartInvocations
by bin(1d) as TimeRange, @memorySize / 1000000 as MemoryConfigurationMB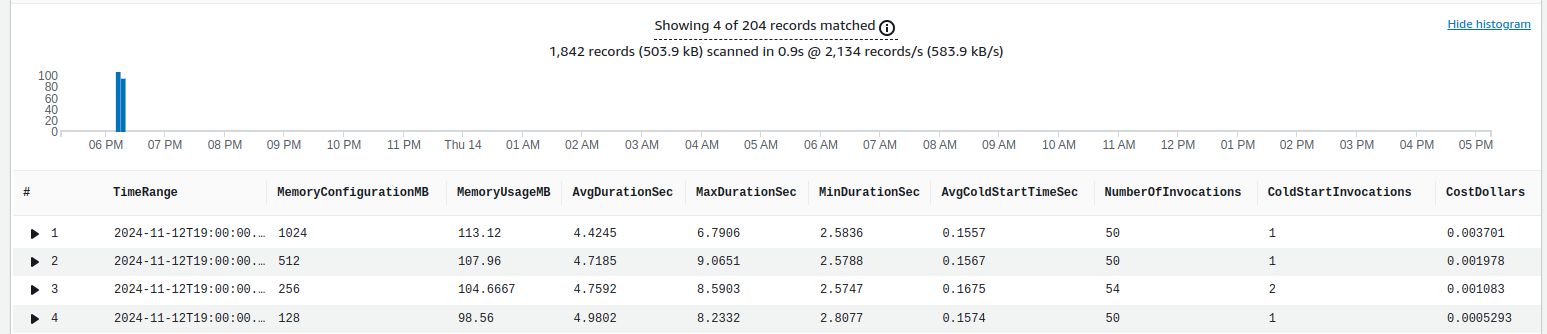
Memory and runtime analysis At the memory configuration of 128MB, the lambda has the lowest average memory usage of 96.1 MB and the highest runtime of 5.1s. At a memory configuration of 1GB, the lambda has the highest average memory usage of 113.1 MB and the lowest runtime of 4.4s. In other words, with an extra ~7MB of memory usage, the lambda function was 700ms faster.
Cold starts analysis ❄️ The average initialization time remains steady around 0.16s.
The chart below shows the power tuner results after running the app 50 times with each of the 4 memory configurations.
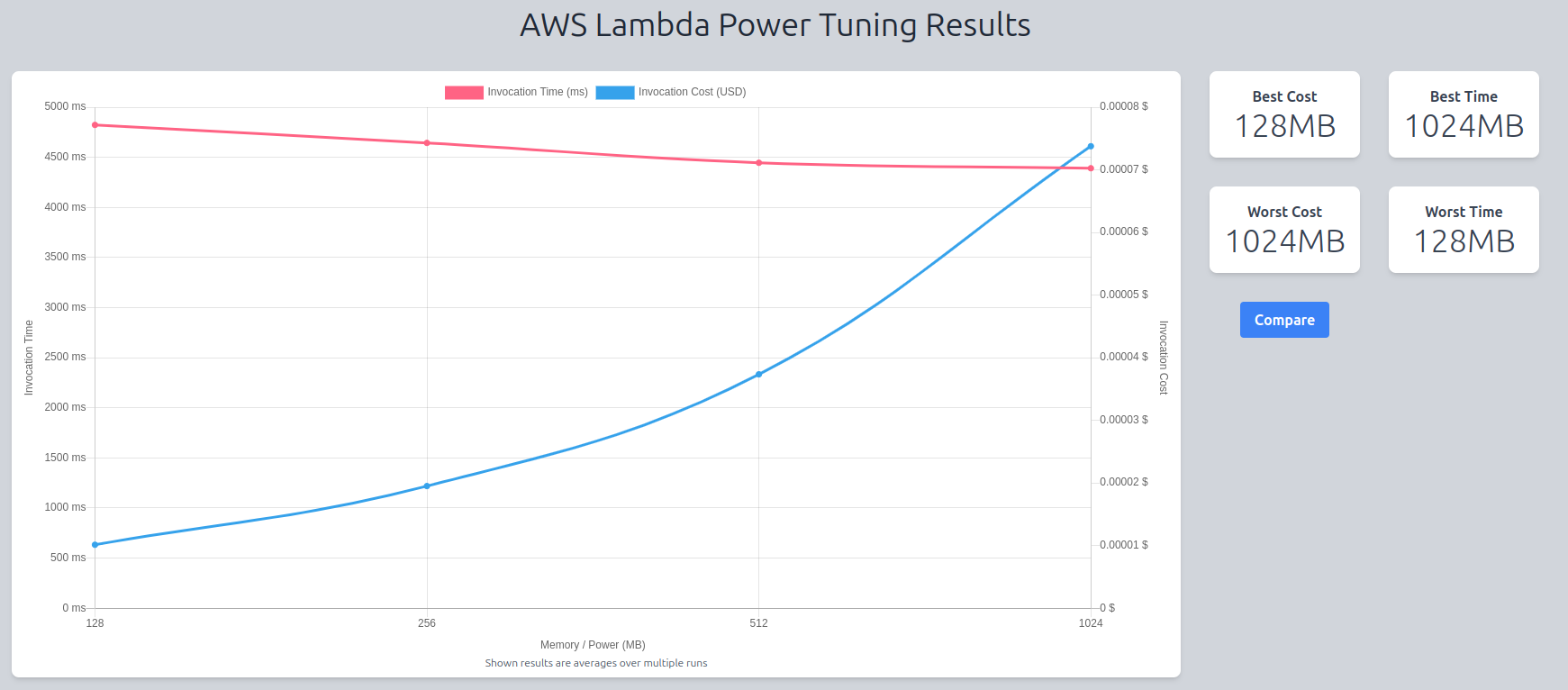
We see that adding memory to the function (and therefore adding computational power) does in fact affect the performance of the lambda by less than a second.
LangChain - Memory, runtime, and coldstarts
Deployment package
We are not able to use zip files for the deployment package of the lambda functions as the zip size exceeds the maximum size allowed by AWS. The loader dependencies and app dependencies create zip files of size around 150 MB.
Instead, we must use container images. The docker image has size 471.45MB using the base python lambda image.

We did the same experiment as with the Rig app above and got the following metrics:

First of all, the function is unable to run with a memory allocation of 128MB. It gets killed at this allocation size due to lack of memory. So we will compare the three following memory configurations: 256MB, 512MB, 1GB.
Memory and runtime analysis At the memory configuration of 256MB, the lambda has the lowest average memory usage of 245.8 MB and the highest runtime of 4.9s. At a memory configuration of 1GB, the lambda has the highest average memory usage of 359.6 MB and the lowest runtime of 4.0s. In other words, with an extra ~113MB of memory usage, the lambda function was 1s faster.
Cold starts analysis ❄️ The average initialization time increases as the memory configuration increases with the lowest being 1.9s and the highest being 2.7s.
The chart below shows the power tuner results after running the app 50 times with each of the 4 memory configurations.
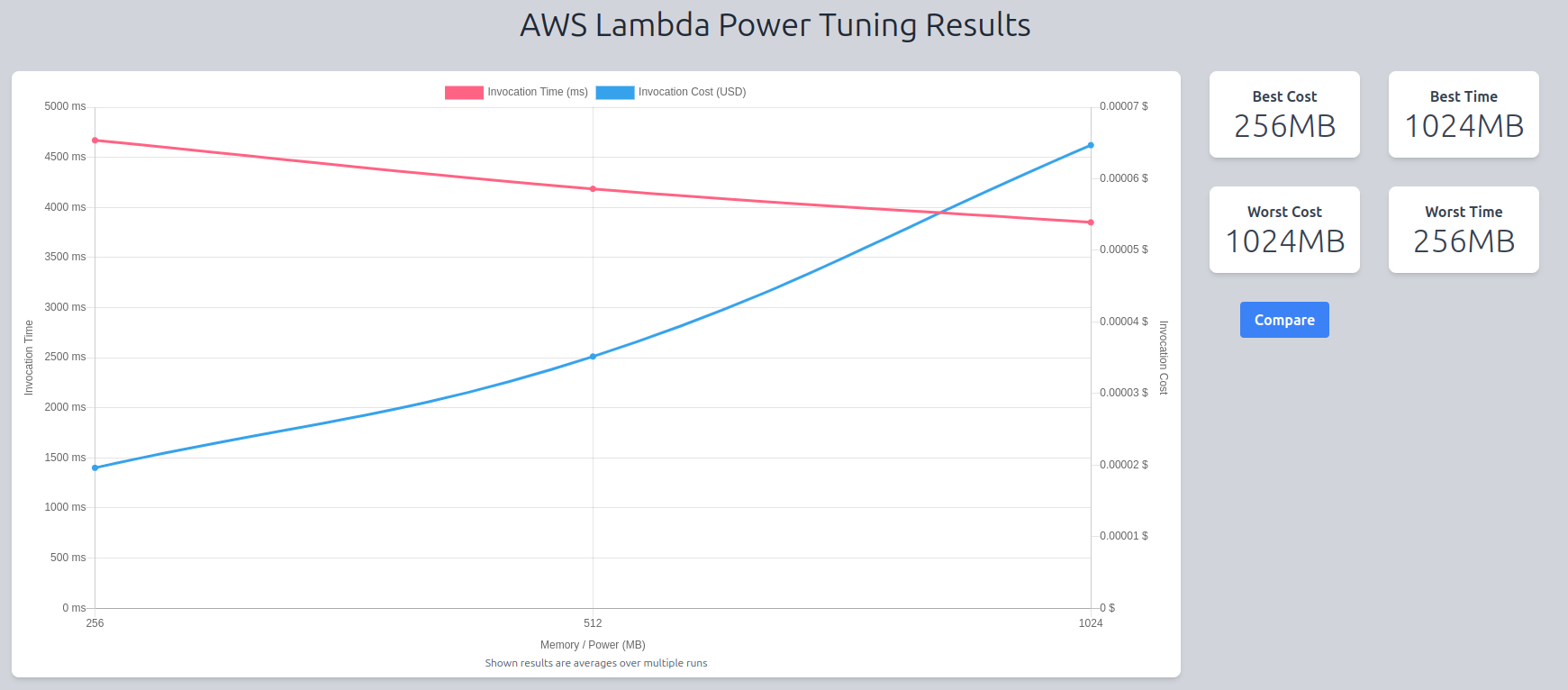
We see that adding memory to the function (and therefore adding computational power) also affects the performance of the lambda by about a second.
Final Comparison between Rig and LangChain
Based on the Cloudwatch logs produced by both the Rig and Langchain lambdas, we were able to produce the following graphics: